آخر المواضيع المضافة

 النبات
الحيوان
الأحياء المجهرية
علم الأمراض
التقانة الإحيائية
التقنية الحيوية المكروبية
التقنية الحياتية النانوية
علم الأجنة
الأحياء الجزيئي
علم وظائف الأعضاء
الغدد
المضادات الحيوية
النبات
الحيوان
الأحياء المجهرية
علم الأمراض
التقانة الإحيائية
التقنية الحيوية المكروبية
التقنية الحياتية النانوية
علم الأجنة
الأحياء الجزيئي
علم وظائف الأعضاء
الغدد
المضادات الحيوية| The Principles of Plant Chemistry |


|
|
Read More
Date: 29-10-2015
Date: 20-10-2016
Date: 6-11-2016
|
The Principles of Plant Chemistry
Plant metabolism, like that of all other organisms, is based on the fundamental principles of physics and chemistry that govern inanimate matter. All living creatures grow, respond to stimuli, and reproduce; but these processes, however complex, do not rely on any mystical or metaphysical "vital force." The physical and chemical reactions that occur in living cells can be modeled by hypotheses and verified by experimentation and observation. The bodies of plants and other organisms are made of atoms drawn from soil, air, or water, and the energy that drives their metabolism is produced by ordinary chemical reactions. It is easy to assume that living organisms must possess special properties because they seem too elaborate to be the result of ordinary chemical and physical processes. This was the predominant view until the 1800s, when three major discoveries were made. It was found that biological compounds could be synthesized in the laboratory using inorganic chemicals and ordinary chemical processes. Next, enzymes were extracted from yeast cells, and some steps of fermentation were carried out in vitro (Table 1) without the presence of living cells. Finally, Louis Pasteur proved definitively that spontaneous generation does not occur and that there is no such thing as "vital force." These advances, along with the discovery of evolution by natural selection, revolutionized the study of metabolism and showed that analytical techniques and laws of physics, chemistry, and mathematics are sufficient to understand metabolism.
TABLE 1: In Vitro and in Vivo
in vitro: in glass. This refers to studies performed in test tubes, flasks, Petri dishes, and similar containers in which some aspect of metabolism is manipulated in laboratory conditions and the metabolic system has been removed from the organism. Photosynthesis might be studied in vitro by breaking cells open, extracting their pigments and enzymes, and examining how they work by supplying or withholding substances such as carbon dioxide and oxygen or by changing the acidity, temperature, or light.
in vivo: in life. This refers to studies carried out with intact cells or whole organisms, whether in natural settings or in a laboratory. Photosynthesis might be studied in vivo by growing whole plants in bright or dim light, low or high levels of carbon dioxide, and other pairs of variables.
ATOMS AND MOLECULES CHEMICAL BONDS
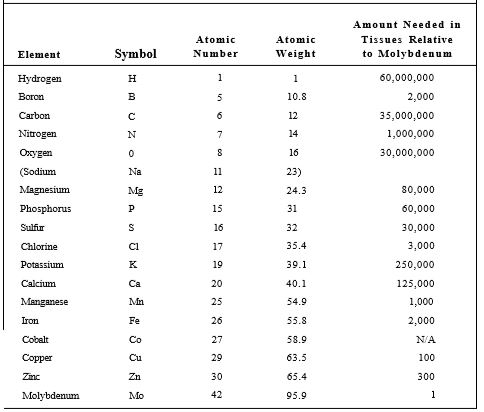
There are 92 natural elements, each differing from the others by the number of protons in the nuclei of its atoms (Table 2). The lightest, hydrogen (H), has only one; the heaviest, uranium (U), has 92. Atomic nuclei also contain neutrons in numbers roughly equal to protons (Fig. 1); neutrons affect only the weight of the atom, not its chemical properties. Around each nucleus are electrons with a negative charge, so each neutralizes the positive charge of a proton. Because of their opposite charges, protons attract electrons, and atoms with equal numbers of protons and electrons are electrically neutral. Electrical attraction is not the only important factor in determining the number of electrons associated with a nucleus.
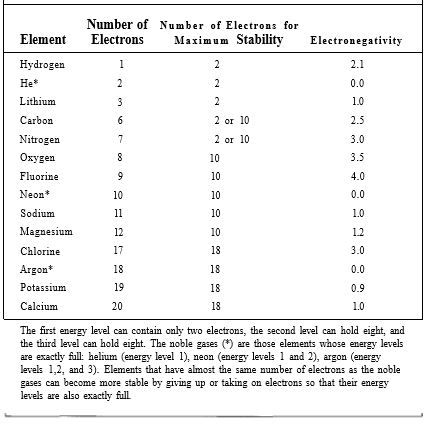
TABLE 2 :Essential Elements
Electrons fit only into specific orbitals and energy levels around the nucleus, and some arrangements are more stable than others (Fig. 2). Helium, neon, and argon, for example, have their outermost energy levels exactly filled with electrons; this is the most stable arrangement possible and also results in equal numbers of electrons and protons, so the atoms are electrically neutral. If one of these atoms loses an electron, it has both an electrical charge (+1) and an unfilled energy level, which is an unstable arrangement. If an atom gains an electron, it again has an unbalanced charge (-1), and the electron is located alone in an orbital of a higher energy level, which is also unstable. Helium, neon, and argon have virtually no tendency to gain or lose electrons or to react with anything; they are called noble gases.
Chlorine, however, even when it is electrically neutral with 17 electrons matching its 17 protons, is not stable. Its outermost energy level (the third level) has its four orbitals full except for one, which contains a single unpaired electron (Table 3). Each atom has an extremely strong tendency to absorb one more electron and complete this energy level; this gives the atom a negative charge (Cl-), which tends to make it slightly unstable, but the new arrangement of 18 electrons is so much more stable that it more than compensates. In plants and animals, chlorine almost always has an extra electron, making it the chloride ion, Cl-. An atom or molecule that carries a charge is an ion; a negative ion is an anion. Sodium is just the opposite (Table 3); when electrically neutral, it has one electron in an orbital by itself. Although losing the electron causes the atom to become the sodium ion Na+, the remaining electrons are in such stable orbitals with energy levels 1 and 2 exactly filled that this arrangement is favored. A positive ion is a cation. This tendency of electrons to move to the most stable possible configuration, which has been named electronegativity, is the driving force behind chemical reactions. The element with the greatest affinity for electrons, fluorine, has an electronegativity of 4.0 (Table 3); the noble gases, with no affinity for extra electrons, have electronegativities of 0.0. Only electrons in the highest, partially filled energy level, called valence electrons, are involved; they are responsible for forming chemical bonds. Although an atom such as sodium may have a strong tendency to lose an electron, electrons virtually never fly off into space; instead, they move from one atom to another during a chemical reaction. Imagine a reaction between an atom with low electronegativity, such as sodium, and one with high electronegativity, such as chlorine. Both elements become more stable by the transfer of a valence electron from sodium to chlorine (Fig. 3).
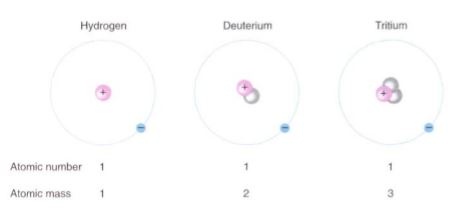
FIGURE 1 :The three isotopes of hydrogen differ in the number of neutrons they contain. Because they all have the same number of protons, they have the same atomic number; they are the same chemical element and have identical properties. Neutrons only cause atoms to move more slowly.
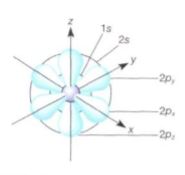
FIGURE 2: The lowest energy level for electrons (1s) contains only one orbital; it is drawn here as a sphere centered on the nucleus. The electron may be found anywhere on the sphere. Any orbital can contain either one or two electrons, but no more; hydrogen contains one; helium, with two protons and two electrons, contains two. In all elements with more than two electrons, the first orbital is filled with two electrons and the remaining electrons are placed in other orbitals at higher energy levels. The next level beyond that of hydrogen and helium contains four orbitals: one spherical (2s) and three that are dumbbell shaped (2p). In neon (atomic number 10), all four orbitals in the second energy level are filled with two electrons each, as is the orbital of the first energy level. This is an extremely stable configuration.
TABLE 3: Energy Levels and Electronegativity
It is important to emphasize that by more stable we mean that the atoms have less energy. This is always the case: A particle is more stable when it has less energy. When sodium reacts with chlorine, both partners have less energy after the reaction, so energy is liberated to the surroundings. Such an energy-releasing reaction is exergonic; if energy is released as heat, the reaction is also exothermic. Another exergonic reaction is the burning of hydrogen with oxygen; two hydrogen atoms transfer one electron each to an oxygen atom, resulting in water:
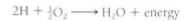
This reaction can be forced to run backward by adding electrical energy, as in the electrolysis of water to form hydrogen gas and oxygen gas. Because the two products of the reverse reaction have more energy than water (they absorb it from the electrical apparatus), the reverse reaction is endergonic (endothermic if energy is absorbed in the form of heat). Any endergonic reaction needs a source of energy—an exergonic reaction occurring somewhere. For water electrolysis, the exergonic reaction is the burning of coal at the electricity-generating station. Another endergonic reaction is the formation of carbohydrates in leaves during photosynthesis; the exergonic reactions for this are the thermonuclear reactions in the sun—even though it is 93 million miles away.
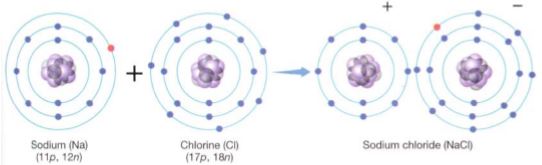
FIGURE 3 :Transferring its single unpaired valence electron gives sodium a stable arrangement (2 + 8) and gives chlorine the electron it needs to have all its energy levels full (2 + 8 + 8).
In the sodium/chlorine reaction, a valence electron is actually transferred from one atom to another, converting each into an ion; in a molecule of salt, NaCl, the ions are held together by ionic bonds. However, in the hydrogen/oxygen reaction, the transfer is not complete; instead the valence electrons are shared between the nuclei (Fig. 4a). Electron sharing has an extra benefit: All electrons are in the most stable orbitals and no build-up of electrical charge occurs. Instead of two H+ and one O2-, the result is just H2O. A bond in which electrons are shared is described as a covalent bond. Whether an ionic bond or a covalent bond forms depends to a large degree on the difference in electronegativities of the two reactants.
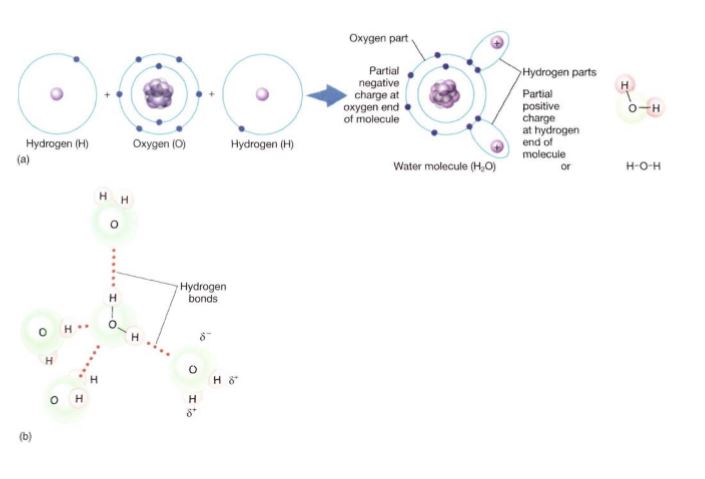
FIGURE 4: (a) Oxygen's affinity for electrons is not great enough to pull valence electrons completely away from hydrogen; instead, electrons are shared but spend more time near the oxygen than near the hydrogen. No ions are formed. (b) In a mass of water, all molecules are held weakly to their neighbors by hydrogen bonds. Each bond has little stabilizing effect, but because every molecule has hydrogen bonds, the cumulative effect is significant.
WATER
Electrons are often not shared equally; in water, electrons spend more time near the oxygen, which has an electronegativity of 3.5, and less time near the hydrogen, which has an electronegativity of 2.1. Therefore, the oxygen in water has a partial negative charge (d-) and each hydrogen has a partial positive charge (d+). The orbitals are oriented so that both hydrogens and their partial positive charges are on one side of the molecule. The molecule is thus polar, with a slightly negative end and a slightly positive end.
Hydrogen Bonding. When two water molecules come close to each other, the positive charge of one slightly attracts the negative end of the other. This is called hydrogen bonding. It is not nearly enough force to pull electrons from one to the other or even enough to cause the two molecules to adhere firmly to each other, but it is sufficient to cause them to adhere slightly (Fig. 4b). As a result, water is a rather sticky, viscous substance that can absorb a great deal of energy without warming rapidly and requires a large amount of energy to convert to vapor. Without the stickiness caused by hydrogen bonding, water molecules in plants could not be lifted from the roots to the leaves. Substances that carry no unbalanced electrical charge, not even a partial one, are nonpolar substances, and they do not undergo hydrogen bonding. Consequently, nonpolar substances move easily past each other and flow with little viscosity. When energy is supplied, nothing holds the molecules in place and slows them, so their speed quickly increases, raising their temperature. They also boil and turn to a gas even at a low temperature, with little energy needed. Examples are methane (see Fig. 6) and acetylene (see Fig. 9).
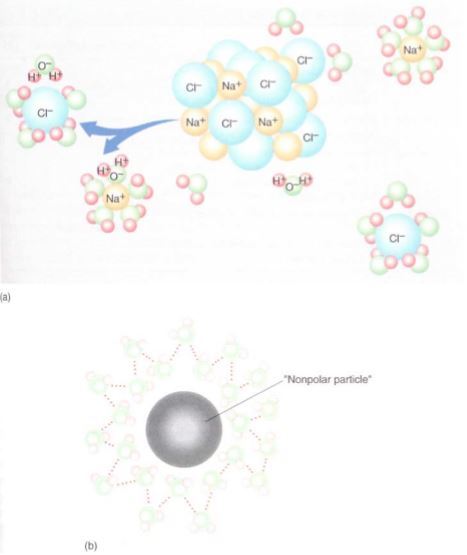
FIGURE 5: (a) When a polar material like ordinary table salt, NaCl, is placed in water, the negative ends of water molecules are attracted to the sodium ions and the positive ends are attracted to the chloride ions, forming weak bonds with them. The new bonding is about the same strength as the waterwater hydrogen-bonding, so the NaCl molecule can break apart easily. (b) If water molecules were occupying the volume of the nonpolar particle, many (at least 11 in this diagram) new hydrogenbonds could form, release energy, and stabilize the water.
Water Solubility and Lipid Solubility. Many other molecules composed of hydrogen bonded to oxygen also have partial charges and undergo hydrogen bonding. When they are placed in water, water molecules surround them and form hydrogen bonds with them (Fig. 5a). This permits individual molecules to move into the water: The substance dissolves and is water soluble. When a nonpolar substance, which cannot form hydrogen bonds, is placed in water, no interaction occurs between the two types of molecules and the substance does not dissolve. In fact, if a molecule of the substance diffuses into the water, it disrupts the water's own hydrogen bonds—this would be an energy-consuming, endergonic reaction that destabilizes the water (Fig. 5b). If the molecule diffuses out of the water, the water molecules can form new hydrogen bonds and release energy, becoming more stable. If the substance is placed in water and agitated violently, it may mix temporarily, but it gradually separates; oil in water is an example of this.
Acids and Bases. When hydrogen combines with oxygen and forms water, the new bonding orbitals have so much less energy than the nonbonding orbitals that they are extraordinarily stable. For hydrogen to break away from water requires the input of a large amount of energy, enough to raise electrons out of the low-energy, stable bonding orbitals. In pure water this is so rare that only about one molecule in 10 million breaks down into H+ and OH-, a proton and a hydroxyl ion, and when they encounter each other, they recombine and form water immediately. The concentration of H+ is known as the acidity of a solution; it is measured as pH, which is the negative logarithm of the H+ concentration (Table 4). In many substances, hydrogen ions are held less tightly than in water molecules, and they give off protons rather easily; any substance that increases the concentration of free protons is an acid. Hydrochloric acid, HCl, dissolves in water to give H+ and Cl-; the extra H+ donated to the solution means that HCl is an acid. A base is anything that decreases the concentration of free protons; this is usually accomplished by giving off hydroxyl ions that combine with protons and form water, effectively removing free protons. NaOH breaks down into Na+ and OH-; the OH- indicates that it is a base. Acids and bases are important because they contribute protons and hydroxyl ions, which can move onto and off of other compounds present in a solution. Because they carry a + or — charge, when they attach to or detach from a molecule, they affect the charge on the molecule. If a nonpolar, water-insoluble molecule picks up a proton because an acid is present, the nonpolar molecule becomes positively charged and water soluble.
TABLE : 4 Acids and Bases

CARBON COMPOUNDS
The concept of life is almost synonymous with the chemistry of carbon. With six protons in its nucleus and an electronegativity of 2.5 (see Table 3), carbon has properties that are both unique and essential for life. Carbon can easily and stably exist as a neutral atom with six electrons, or it can form covalent bonds by sharing the valence electrons (usually four) of other atoms. For instance, in methane (CH4) one carbon atom shares one electron with each of four hydrogen atoms (Fig. 6), and in carbon dioxide (CO2) it shares two electrons with each of two oxygen atoms. In fatty acids, most carbon atoms share two electrons with each of two hydrogens and each of two more carbons . Because carbon reacts so readily with more carbon, it can form long chains and complex ring structures.
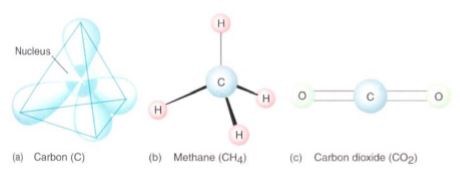
FIGURE 6: When an atom shares electrons with another atom, the bonding orbitals have shapes and orientations different from those of isolated atoms, as shown in Figure 2 (a) and (b) If carbon bonds to four other atoms, the bonding orbitals point to the four corners of a tetrahedron, which separates each orbital as much as possible from the others. (c) If carbon bonds to only two other atoms, two double-bond orbitals point exactly away from each other.
Carbon can form three types of covalent bonds, depending on how many other atoms it shares electrons with. If there are four other atoms (methane, fatty acids), the carbon is linked by single bonds, each bonding orbital containing one electron from the carbon and one from the other atom. These bonding orbitals are arranged in a tetrahedron (Fig. 2.6). In a chain of carbons, the carbon backbone is zigzag, not straight (Fig. 7). Carbon can form a double bond by sharing two of its electrons with one other atom that also contributes two electrons. The other two valence electrons of carbon may be in a second double bond or in two single bonds. If two sets of double bonds are present, as in carbon dioxide, the two sets extend in opposite directions, producing a straight molecule (Fig. 6). If one double bond and two single bonds are present, the molecule is flat and shaped like a Y (see Fig. 8). The double bond is extremely rigid and the arms cannot rotate around the carbon. Many organic molecules have carbon-carbon double bonds, and because the double bond cannot rotate, there are two possible forms of
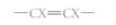
With both Xs on the same side, they are in the cis position and when on opposite sides in the trans position. The cis form has physical and metabolic properties that differ from those of the trans form.
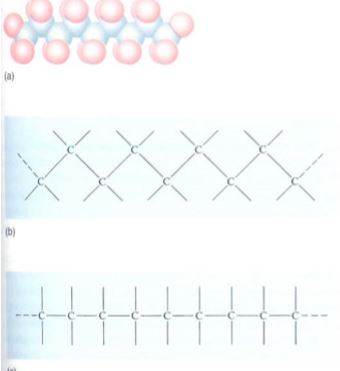
FIGURE 7: (a) A series of carbon atoms bonded to other carbons by single bonds would look something like this, with the blue spheres representing carbon atoms and the red spheres representing other atoms attached to the carbons. Because the bonds are arranged as a tetrahedron, the carbon backbone has a zigzag shape. (b) and (c) are simpler ways of showing the structure in (a).
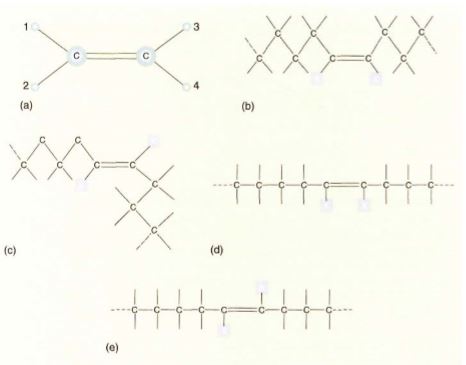
FIGURE 8: (a) The carbon-carbon double-bond system is flat: All atoms in this structure are in the same plane. Furthermore, the double bond cannot rotate, so atom 1 cannot change position with atom 2; if the carbon-carbon bond were a single bond instead, such a rotation could occur thousands of times every second. (b) to (e) are simplified ways of presenting carbon chains with one double bond. In (b) and (d), the Xs are in the cis position. In (c) and (e) they are in the trans position.
Rarely, carbon forms a triple bond by sharing three of its valence electrons with one other atom (Fig. 9). The triple bond is not very stable (its electrons still have a great deal of energy), and triple bonds tend to be broken easily.

FIGURE 9: The carbon-carbon triple bond is extremely rare; the extra valence electrons are shown here forming single bonds with hydrogen. This molecule is acetylene.
ORGANIC MOLECULES AND POLYMERIC CONSTRUCTION
FUNCTIONAL GROUPS
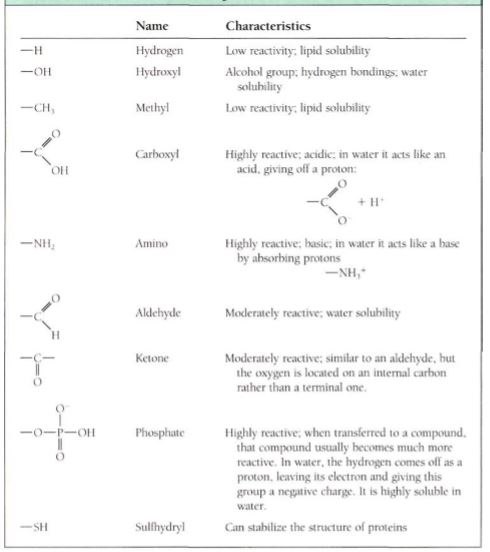
Millions of carbon compounds are possible, varying not only in the number of carbons they contain but also in the types and numbers of noncarbon atoms, types of bonds, and other factors. This great diversity of carbon compounds actually consists of a small number of families of compounds whose members have similar properties. This is because the properties of a compound are due mostly to the chemical groups, known as functional groups, attached to the carbon atoms (Table 5). Because carbon compounds can be large, each may have many functional groups of various types, being simultaneously both acids and alcohols, acidic and basic, or lipid soluble in some regions and water soluble in others.
Table 5: Functional group
POLYMERIC CONSTRUCTION
A polymer is a large compound composed of a number of more or less identical subunits (monomers). The simplest example is construction using bricks. The bricks (monomers) are virtually identical, but they can be used to construct many different things: houses, lecture rooms, sidewalks. Simple sugars like glucose are monomers that can be polymerized into starch, cellulose, mucilage, and many other polymers. Polymeric construction is essential to life for several reasons. First, it reduces the difficulty of construction; to build a brick building, it is only necessary to know how to make bricks and how to assemble them. If a different type of building is needed, only the assembly information needs to be changed, not the mechanism for making bricks. With sugars, for the plant to make starch, it bonds glucose together with a certain type of bond; to make cellulose, it uses a different type of bond. But the mechanism for making glucose does not change.
Polymeric construction allows an organism to have a simple basic metabolism that produces only a few types of monomers. As the physiology changes, only the assembly of monomers changes, not the basic metabolism. For example, as a plant grows, it assembles amino acids into proteins necessary for leaves and stems. At the right time, it begins to assemble the same types of amino acids into different proteins—those necessary for flowers. Even more dramatic, algae have the same sugars and amino acids as flowering plants. During 400 million years of evolution, only the types of proteins formed have changed; the basic mechanism for producing the amino acid monomers is about the same. Polymeric construction also permits recycling and conservation of resources; once a polymer is no longer needed, it can be depolymerized back to its monomers, which are then used in the construction of a new polymer. All the energy expended in their construction is conserved. Finally, polymeric construction allows various parts of an organism to work together in construction. As a fertilized egg grows into an embryo in the developing seed, surrounding tissues supply it with sugars, amino acids, and fats. The embryo can quickly assemble these into organelles and grow rapidly. If the tissues supplied the fertilized egg only with carbon, oxygen, nitrogen, and other elements, growth would be much slower.
CARBOHYDRATES
Carbohydrates are defined by two criteria. First, they usually contain only carbon, hydrogen, and oxygen, although a few carbohydrates contain atoms such as nitrogen or sulfur. Second, the ratio of hydrogen to oxygen is close to 2:1, the same ratio as in water; the generalized chemical formula for carbohydrates is (CH2O) n.
MONOSACCHARIDES
The simplest carbohydrates are the monosaccharides, or simple sugars, glucose being a familiar example. Monosaccharides are small molecules classified by the number of carbon atoms each contains: four- (4C; tetrose), five- (pentose), six- (hexose), seven-carbon sugars, and so on. The pentoses and hexoses are by far the most abundant and most important (Table 6; Fig. 9).
Various sugars in a class may have the same chemical formula but differ in their atomic arrangements; such molecules are called isomers. For example, glucose and fructose are isomers, both having the formula C6H12O6 but having different chemical structures. Because the functional groups of glucose are arranged differently from those of fructose, the two molecules have distinct shapes and different chemical properties. The differences in chemistry are actually quite slight, but the differences in shape are extremely important. In order for an enzyme to catalyze a reaction, the substrate molecules must fit physically into a very precisely shaped active site. Glucose can enter the active site of certain enzymes, but fructose and other hexoses cannot. Enzymes easily distinguish between isomers by their unique shapes.
Monosaccharides are flexible because all their carbon-carbon bonds are single bonds, not flat, rigid double bonds. When dissolved in water, the molecules flex and rotate around each carbon atom, changing shape thousands of times every second. When one end of a molecule comes close enough to the other end, the two ends may react, forming a closed ring (Fig. 9). In glucose the number 1 carbon reacts with the —OH group on the number 5 carbon, forming a six-member ring that has oxygen as part of the ring and —CH2OH as a side group. Ring formation releases energy (it is exergonic), and the ring form is the more stable, more common form for a hexose dissolved in the water of a cell.
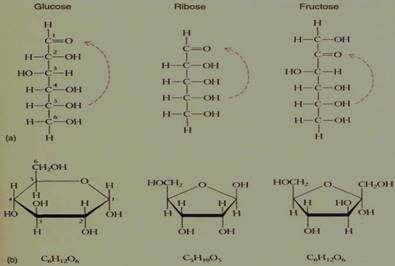
FIGURE 9: (a) Ribose is a 5C sugar, a pentose; glucose and fructose are both hexoses (6C). (b) Each sugar can also exist in ring form, but ring formation involves the aldehyde or ketone functional group, which thus does not exist in the ringform sugars.
Because of ring formation, monosaccharides tend to be rather unreactive, relatively inert molecules, which is ideal for physiological functions such as construction, transport, and energy storage. Monosaccharides can be used to build structures that must be inert, stable, and long lasting. They can be transported from region to region without causing damage by reacting with structures they encounter. Monosaccharides can store energy: They are synthesized in leaves from carbon dioxide and water in an extremely endergonic process—photosynthesis. Once formed, the energy-rich, stable simple sugars can be moved to sites where energy is needed, such as flowers or roots; then they are metabolized, releasing energy at the new location. Animals and fungi use the monosaccharide glucose for transport, but most plants use sucrose, a disaccharide composed of one glucose molecule plus one fructose molecule.
POLYSACCHARIDES
Monosaccharides can act as monomers, reacting with other monosaccharides to form polymers called polysaccharides. Extremely short polysaccharides, less then about ten mono-saccharides long, are called oligosaccharides and are named by the number of sugars they contain: disaccharides such as sucrose, trisaccharides, and so on.
Theoretically, many types of oligosaccharides and polysaccharides are possible. Consider polysaccharides that consist of just glucose: These could be di-, tri-, tetrasaccharides, and so on, each longer and heavier than the previous one. The bond between two monosaccharides results from the interaction of an —OH group on each (Fig. 10), so there are numerous possible disaccharides of glucose, each based on the position of the linking bond. During bond formation an entire —OH is removed from one carbon, a hydrogen is removed from the other —OH group, and water is formed; this is a dehydration reaction. Reversal of this, breaking the bond by adding water back to it, is hydrolysis.
Despite the large number of polysaccharides that are theoretically possible, very few types actually exist. The dehydration reaction is endergonic and must be forced to proceed by being coupled with an energy-producing reaction. If the cell does not provide an exergonic reaction to power the polymerization, that particular polysaccharide is not formed to any significant extent; the reaction equilibrium does not favor it. Also, the energy-of-activation barrier of polymerization is high, so the reaction must be catalyzed by an enzyme. This gives the organism great metabolic control; natural selection favors the evolution of enzymes that mediate the production of useful polysaccharides. A mutation resulting in an enzyme that mediates the formation of a harmful or useless polysaccharide would be disadvantageous and would probably become extinct. Of the few polysaccharides that actually are formed by plants, three are especially important.
Starch. Starch, technically known as amylose and amylopectin, is a long polysaccharide composed only of glucose residues (Fig. 11). The enzyme responsible for polymerization (starch synthetase) recognizes only glucose molecules; these fit onto the enzyme such that the only two functional groups that ever form bonds are the —OH groups of the number 4 carbon of one glucose and the number 1 carbon of the other. Because of the way the glucoses are oriented (both face the same direction), the bond is called an alpha-1, 4-gly- cosidic bond.
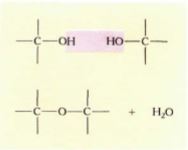
FIGURE 10: Because —OH is such a common functional group, many monomers combine by means of dehydration reactions.
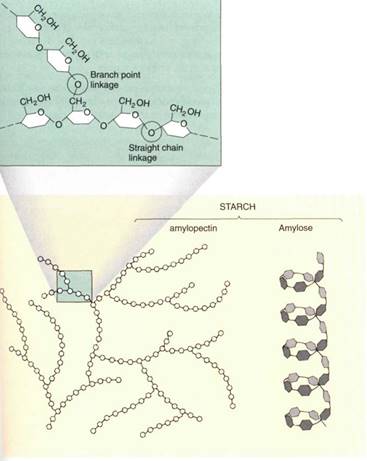
FIGURE 11: If glucoses are linked to other glucoses by alpha-1, 4glycosidic bonds, the result is an unbranched, coiled chain called amylose, the main component of starch. A second enzyme occasionally makes a bond with the number 6 carbon, resulting in an alpha-1, 6-branchedchain amylopectin, also a component of starch .
Cellulose. A set of enzymes called cellulose synthases polymerizes glucose molecules into the polymer cellulose . The glucose residues have an alternating orientation, and the resulting bond is a beta-1, 4-glycosidic bond. This is critically important to the nature of the polymer: Although both amylose and cellulose are unbranched chains of glucose joined at carbons 1 and 4, they are totally distinct chemically and biologically.
Cellulose molecules can form large numbers of hydrogen bonds with other cellulose molecules, crystallizing into rigid aggregates that are extremely strong . On the
:ell surface, cellulose molecules hydrogen bond to other polysaccharides and thus become cross-linked into a complex meshwork known as the cell wall .
Cellulose is remarkably inert; few organisms have enzymes capable of hydrolyzing the beta-1, 4-glycosidic bond. Wood-rotting fungi and bacteria have cellulose-degrading enzymes, but even termites, cockroaches, and cattle can live on cellulose only because their digestive tracts contain microorganisms with the proper enzymes.
Oligosaccharides. Many organisms, especially animals but also some plants, attach short chains of sugars onto proteins. These oligosaccharides are most often present on proteins near or at the cell surface and seem to be involved in cell recognition.
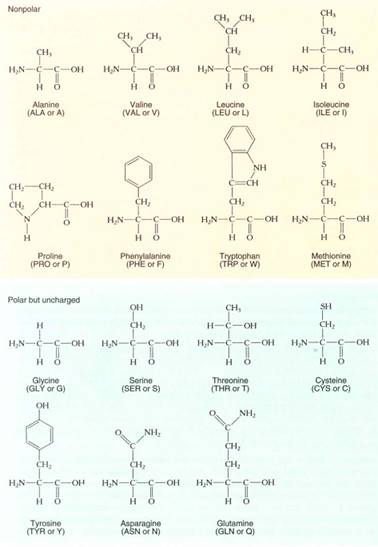
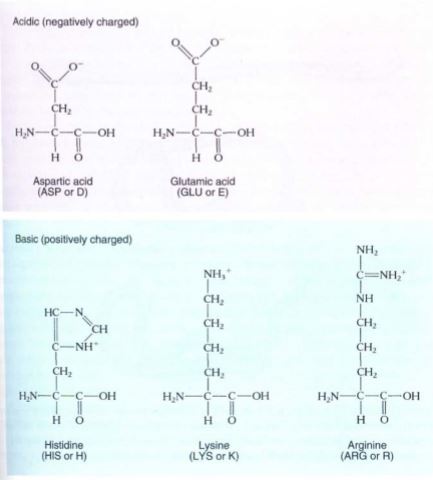
FIGURE 12: The amino acids that occur in proteins. Two systems of abbreviations are used for the names of amino acids—an older system that involves three letters for each, and a newer system that uses just one letter each.
Amino Sugars. In fungi, some sugars contain nitrogen in addition to carbon, hydrogen, and oxygen. These amino sugars are polymerized into long chains that can be completely branched and cross-linked. These polymers, known as chitin, are part of fungal cell walls.
AMINO ACIDS AND PROTEINS
Proteins are unbranched polymers composed of amino acids; they tend to be about 100 to 200 amino acid residues long. Very short proteins, with fewer than about 50 amino acids, are frequently called polypeptides. Twenty amino acids are used for protein synthesis (Fig. 12); each consists of one carbon that carries four side groups: (1) —COOH, the carboxyl group that causes it to be an acid; (2) —NH2, the amino group; (3) —H; and (4) a fourth group "R" that differs from one amino acid to another. The R groups are not involved in polymerization; instead, they protrude to the sides of the protein backbone and their properties determine the property of the protein. The R groups cause amino acids to differ structurally, chemically, and biologically. Some R groups are acidic; others are basic. Nonpolar, hydrophobic R groups give an amino acid a tendency to interact with other nonpolar molecules such as fats and lipids. Polar, hydrophilic R groups cause their amino acids to interact with other polar molecules, avoiding nonpolar ones. Cysteine is unique in having a sulfhydryl in its R group; two sulfhydryls can interact, forming an —S—S— (disulfide) covalent link between two separate cysteines. If the two cysteines are in the same protein, the disulfide link holds the two regions together; if they are in separate proteins, the disulfide links the two proteins. During protein synthesis, the carboxyl group of one amino acid reacts with the amino group of the next, water is removed, and a peptide bond is formed (Fig. 13). This sounds similar to the polymerization of monosaccharides and actually is similar if performed in a test tube. However, within a cell the two types of polymerization are completely different; the linking of amino acids is mediated by organelles called ribosomes and involves large numbers of enzymes and intermediates. This is necessary because proteins are not as simple as polysaccharides; instead, the sequence and types of amino acids incorporated must be controlled with great precision.

FIGURE 13: The peptide bond between two amino acid residues in a protein is formed by the sharing of electrons between a carboxyl carbon and an amino nitrogen. During bond formation, water is removed, so this is a dehydration reaction.
LEVELS OF ORGANIZATION IN PROTEIN STRUCTURE
Primary Structure. The amino acid sequence is the protein's primary structure. Because each amino acid has a unique R group, the sequence of amino acids produces a particular sequence of R groups. If all R groups were similar chemically, like the side groups in monosaccharides, this sequence would not be very important. But the R groups in proteins are chemically diverse, so a protein can have extremely complex properties. Proteins are flexible (all bonds in the backbone are single bonds), and some regions interact with other regions of the same protein, causing the whole molecule to have a characteristic shape (Fig. 14). If the R groups of an entire region are of the correct type, the protein forms a helical structure known as an alpha helix. Alpha helices, which often affect only short regions of protein, are an example of secondary structures. Many proteins do not have secondary structure.
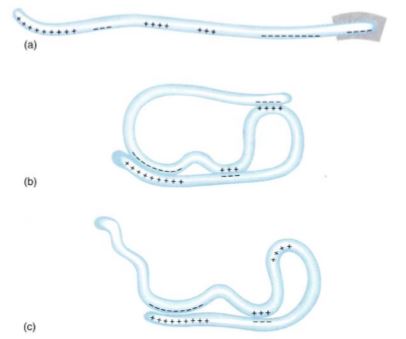
FIGURE 14: (a) The charged amino acids (acidic and basic) of a hypothetical protein. With a different primary structure, the distribution of charges would be different. (b) Various regions of a protein interact, forming a three-dimensional shape, its tertiary structure. (c) If the primary structure lacked the last four negative amino acids (box in (a)), the tertiary structure would be different.
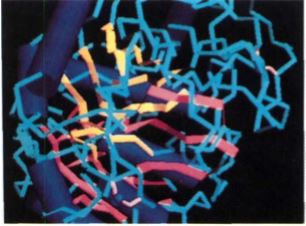
FIGURE 15: A computer-generated model of the enzyme amylase, which breaks amylose down into glucose.
Tertiary Structure. The physical shape of a protein in its functional mode is its tertiary structure, determined largely by primary structure: Positively charged regions attract and bind to negatively charged regions (Fig. 14), and hydrophobic R groups interact and form water-free pockets inside the folded protein. Cysteines may link two portions together with disulfide bonds. The protein's overall shape may be globular or fibrous, but the shape and nature of specific sites are usually much more important. Because most plant proteins are enzymes, the active sites must recognize substrates by shape, electrical charge, or hydrophobic properties (Fig. 15). For example, the tertiary structure of the enzyme starch synthetase must have a site into which glucose and a growing molecule of amylose can fit. Because glucose is water soluble, the R groups near this active site should be hydrophilic. Without the correct primary structure, the protein does not fold into the proper tertiary structure and a functional active site is not formed.
Tertiary structure is also affected by small molecules and ions that are not part of the protein; their concentration in the protoplasm affects the shape and therefore the activity of many enzymes. Magnesium (Mg2+) and calcium (Ca2+) can interact with negatively charged R groups and alter the tertiary structure; with high levels of magnesium or calcium, two negatively charged regions may become "glued" together, whereas without these two cations the negatively charged regions repel. Tertiary structure is affected by pH and heat. Protons and hydroxyl ions released by acids and bases interact with charged R groups, changing the way various regions of the protein attract or repel each other. As proteins are heated, the atoms and molecules vibrate more rapidly and unfold. If heated enough, as in cooking an egg, the proteins unfold completely and become denatured. With enzymes, even dilute acids or bases or just mild heating causes enough of a change in shape to distort the active site, and the enzyme cannot function.
Quaternary Structure. Quaternary structure refers to the interaction between two or more separate polypeptides. Quaternary structure is maintained by hydrogen bonding, the interaction of hydrophobic regions, or disulfide bridges. As with secondary structure, not all proteins have this level of organization, but for many it is critical for proper functioning. Many enzymes consist of two or four polypeptides that must be associated to work properly; only when all are aggregated are the active sites completely formed and functional. For example, an enzyme called RuBP carboxylase (discussed in Chapter 10) is a giant enzymatic complex consisting of eight small proteins and eight large ones; the complex is functional and carries out photosynthesis only when all 16 proteins associate with the proper quaternary structure.
A selective advantage of quaternary structure is that it allows self-assembly of certain structures; once the individual protein monomers are formed, they automatically associate into the proper structure such as a microtubule or an enzyme complex. No special constructing apparatus or metabolism is needed; however, a cell easily controls self-assembly by altering conditions that affect aggregation of the individual proteins. With a change in the concentration of calcium, magnesium, or protons, the charge of some R groups is altered and the protein takes on a new shape, either promoting or inhibiting self-assembly into the quaternary structure.
NUCLEIC ACIDS
Nucleic acids are polymers composed of monomers called nucleotides, but the nucleotides themselves are actually composed of three distinct subunits as well. Each nucleotide is formed by the bonding of (1) a phosphate group, (2) a five-carbon sugar, and (3) a complex ring molecule that contains nitrogen and acts like a base (Fig. 16). Nucleic acids contain only five nitrogenous bases that fall into two groups: Pyrimidines are molecules composed of a single ring, whereas purines consist of two rings (Fig. 17). The pyrimidines are cytosine, uracil, and thymine, and the purines are adenine and guanine. Only two types of five-carbon sugar are ever joined to these nitrogenous bases: ribose and deoxyribose, which differs from ribose in having an —H group at one site where ribose has —OH. The enzymes involved in joining the sugars to the bases have such precisely shaped active sites that they accurately distinguish ribose from deoxyribose. Only four ribonucleotides (ribose-containing nucleotides) occur because thymine is never attached to ribose. Similarly, uracil is never attached to deoxyribose, so only four deoxyribonucleotides occur. Deoxyribonucleotides and ribonucleotides are never mixed together in the same polymer, so nucleic acid polymers are of just two fundamental types: deoxyribonucleic acid (the famous DNA) and ribonucleic acid (RNA). DNA is found in the nucleus as the main component of chromosomes as well as in plastids and mitochondria. As in proteins, the sequence of monomers is critically important, and any change of sequence can have serious effects. In fact, the sequence of deoxyribonucleotides is the genetic information stored in the nucleus. The sequence is used indirectly to guide the polymerization of amino acids into proteins. The primary structure of DNA thus determines the primary structure of proteins and therefore also their secondary, tertiary, and quaternary structures, as well as their function.
Polymers of ribonucleotides, RNA, serve several functions. Some RNA molecules, called messenger RNAs, carry copies of genetic information from the nuclear DNA to ribosomes, the sites of protein synthesis in the protoplasm. Ribosomes are large complexes of enzymes and a second type of RNA, ribosomal RNA. A third class of RNA, transfer RNA, carries amino acids to ribosomes.
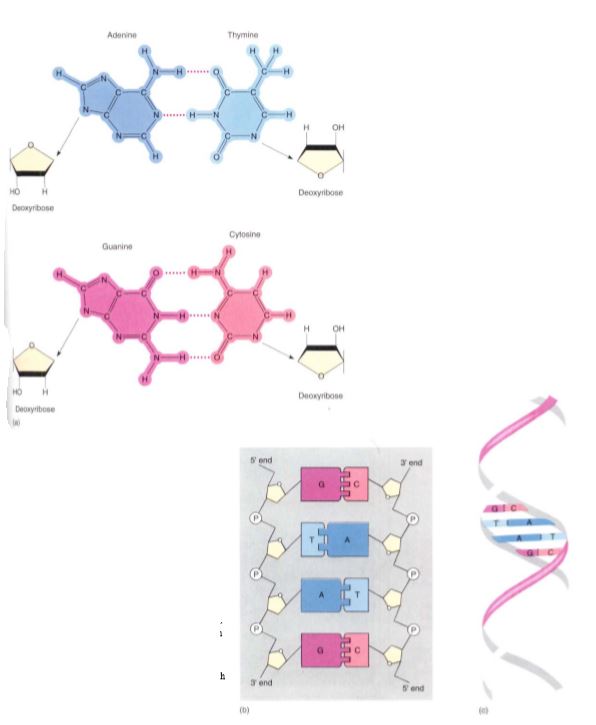
FIGURE 16: (a) DNA contains four bases; adenine can form two hydrogen-bonds with thymine, and guanine can form three with cytosine. Each base is covalently bound to a sugar, deoxyribose. (b) As the monomers—nucleotides— polymerize into nucleic acid, the sugars are bound to each other by phosphate groups, making a long chain with the bases projecting from the side. If the bases of one nucleic acid complement those of another nucleic acid, the two can form thousands of hydrogen-bonds and adhere to each other, making double-stranded DNA. (c) The two nucleic acids are not straight but rather spiral around a common axis, forming a double helix.
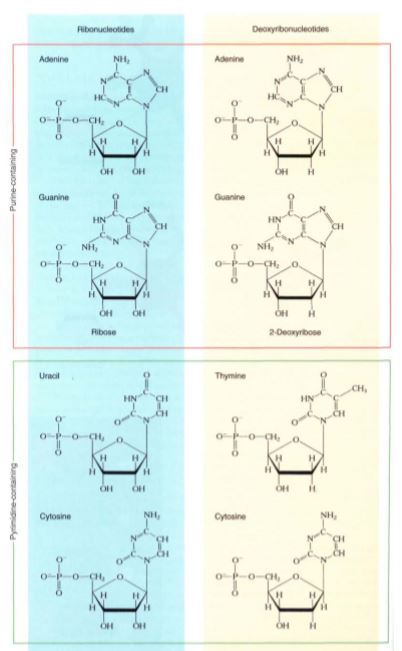
FIGURE 17: Purines (adenine and guanine, in the orange rectangle) contain two rings fused together, and pyrimidines (cytosine, uracil and thymine, in the green rectangle) contain a single ring. The sugar ribose is found attached only to adenine, guanine, uracil, and cytosine (blue panel), whereas deoxyribose is attached only to adenine, guanine, thymine, and cytosine (tan panel). Pyrimidines are pie shaped, and a pie can be cut (cytosine, uracil, thymine).
LIPIDS
Lipids are fats and oil substances that are extremely hydrophobic and water insoluble. Like carbohydrates, they lack nitrogen and sulfur and consist mainly of carbon, hydrogen, and oxygen. Unlike carbohydrates, they have much more hydrogen than oxygen, often having only two oxygen atoms at one end of a long molecule.
The basic units of many lipids are fatty acids. These are long chains containing up to 26carbon atoms with a carboxyl group at one end. If every carbon atom except the carboxyl carbon carries two hydrogens, the fatty acid is saturated; that is, it can hold no more hydrogen (Fig. 18; Table7). All carbon-carbon bonds are single, and all parts of the molecule can rotate; in groups, the molecules tend to straighten and crystallize, being stabilized by interactions with closely packed adjacent fatty acids. Because of this tendency to crystallize, saturated fatty acids are solid at room temperature (Fig. 19).
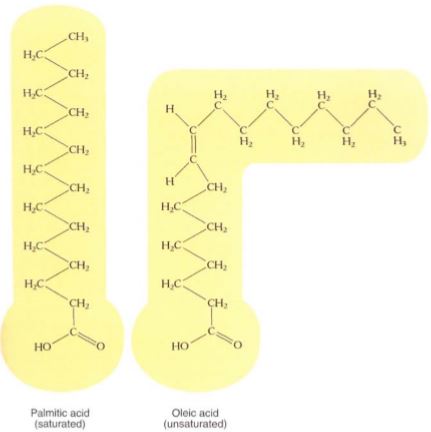
FIGURE 18: All fatty acids have a carboxyl group at one end; the rest of the molecule is just carbon and hydrogen. Fatty acids differ in the number of carbon atoms and double bonds they contain. If no double bond is present (that is, the molecule is saturated), the molecule can be straight; if a double bond is present (the molecule is unsaturated), the molecule must be kinked at that point.

FIGURE 19: Saturated fats, such as butter or margarine, are so orderly that they can crystallize and require considerable heat to melt, whereas unsaturated fats (oils) are so irregular that they melt even while cool.
If some of the carbons are double bonded to adjacent carbons, the fatty acid is unsaturated; the carbon-carbon double bonds are rigid and the molecule has a kink. With several double bonds (polyunsaturated), the molecules are irregular in shape and cannot align well; they have little tendency to crystallize and they remain liquid and oily rather than solid.
Table 7: Common fatty acids

POLYMERS OF FATTY ACIDS
Cutins and Waxes. Fatty acids tend to polymerize readily with each other, especially when exposed to oxygen. Plants secrete fatty acids through the outer wall of their epidermal cells, and these polymerize when they come into contact with oxygen. If the fatty acids are relatively short, the polymer is cutin, but if the fatty acids are longer, the polymer is wax (see Fig. 20). Cutin and wax are not orderly, linear, well-defined polymers like polysaccharides, proteins, or nucleic acids. Instead, cross-linking between fatty acids can occur almost anywhere, and complex three-dimensional tangles result. Furthermore, the fatty acids involved are mixtures of long-chain and short-chain, saturated and unsaturated, fatty acids. The resulting cutin or wax can be extremely heterogeneous and variable from area to area. Both cutin and wax are waterproof and help reduce water loss from the plant body. They also prevent fungi from invading epidermal cells.
Triglycerides. Triglycerides are composed of three fatty acids combined with one molecule of glycerol (Fig. 20a). The three fatty acids within a single triglyceride vary in length and degree of saturation and thus affect the nature of the triglyceride.
Phospholipids. Phospholipids contain glycerol, two fatty acids, and a phosphate group (Fig. 20b). This composition is critically important: In triglycerides, all parts of the molecules are hydrophobic, so if they are mixed with water, they coalesce into spherical droplets, the shape that has a minimum surface area exposed to water (see Fig. 2.5b). But the phosphate group of phospholipids is extremely hydrophilic, so these molecules have one end that tends to dissolve in water and one end that repels water. When mixed with water, they form a layer one molecule thick across the top of the water; this is the shape that
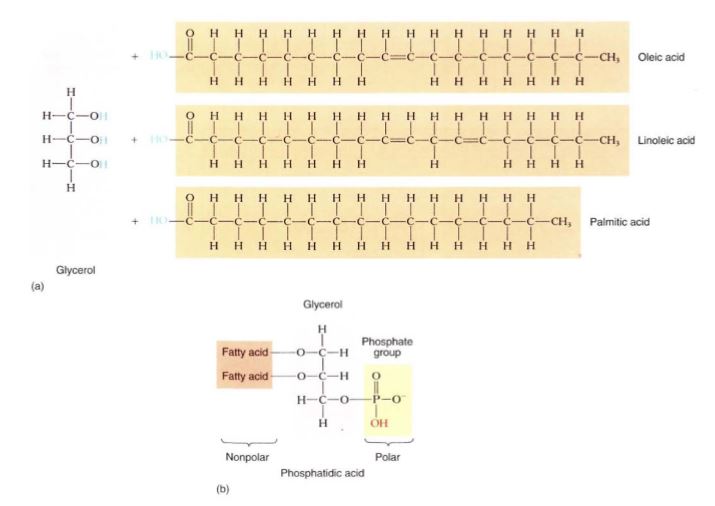
FIGURE 20: (a) In a triglyceride, the carboxyl group on each fatty acid reacts with a hydrogen group on the glycerol in a dehydration reaction. All parts of this molecule are nonpolar. These are extremely hydrophobic: In order for even one of these molecules to diffuse into water, hundreds of waterwater hydrogen bonds would have to be broken. (b) A phospholipid is nonpolar on one end, polar on the other. The polar end can dissolve into water; the nonpolar end can dissolve into fats.
allows both maximum interaction of phosphates with water and minimum interaction of the hydrophobic portion with water. In cells, phospholipids form two-layered membranes, the hydrophobic layer of one contacting the hydrophobic layer of the other. This dual nature of both repelling and attracting water is exactly the property needed to build biological membranes. Once formed, the membranes stabilize by interacting with proteins that have shapes (tertiary structures) with regions of positive charges that interact with the phosphate groups.

|
|
|
|
دراسة يابانية لتقليل مخاطر أمراض المواليد منخفضي الوزن
|
|
|
|
|
|
|
اكتشاف أكبر مرجان في العالم قبالة سواحل جزر سليمان
|
|
|
|
|
|
|
اتحاد كليات الطب الملكية البريطانية يشيد بالمستوى العلمي لطلبة جامعة العميد وبيئتها التعليمية
|
|
|