آخر المواضيع المضافة

 النبات
الحيوان
الأحياء المجهرية
علم الأمراض
التقانة الإحيائية
التقنية الحيوية المكروبية
التقنية الحياتية النانوية
علم الأجنة
الأحياء الجزيئي
علم وظائف الأعضاء
الغدد
المضادات الحيوية
النبات
الحيوان
الأحياء المجهرية
علم الأمراض
التقانة الإحيائية
التقنية الحيوية المكروبية
التقنية الحياتية النانوية
علم الأجنة
الأحياء الجزيئي
علم وظائف الأعضاء
الغدد
المضادات الحيوية| Group I Introns Form a Characteristic Secondary Structure |


|
|
Read More
Date: 30-12-2015
Date: 17-3-2021
Date: 10-5-2016
|
Group I Introns Form a Characteristic Secondary Structure
KEY CONCEPTS
- Group I introns form a secondary structure with nine duplex regions.
- The cores of regions P3, P4, P6, and P7 have catalytic activity.
- Regions P4 and P7 are both formed by pairing between conserved consensus sequences.
- A sequence adjacent to P7 base pairs with the sequence that contains the reactive G.
All group I introns can be organized into a characteristic secondary structure with nine helices (P1–P9). FIGURE 1 shows a model for the secondary structure of the Tetrahymena intron. Although structural analyses were able to elucidate the secondary structure of the group I intron, it was not until the determination of the crystal structure that the tertiary structure of the intron was revealed. Several crystal structures of group I introns have been solved, and these confirm previous models of the secondary structure. Two of the base-paired regions are generated by pairing between conserved sequence elements that are common to group I introns.
P4 is constructed from the sequences P and Q; P7 is formed from the sequences R and S. The other base-paired regions vary in sequence in individual introns. Mutational analysis identifies an intron “core” containing P3, P4, P6, and P7, which provides the minimal region that can undertake a catalytic reaction. The lengths of group I introns vary widely, and the consensus sequences are located a considerable distance from the actual splice sites.
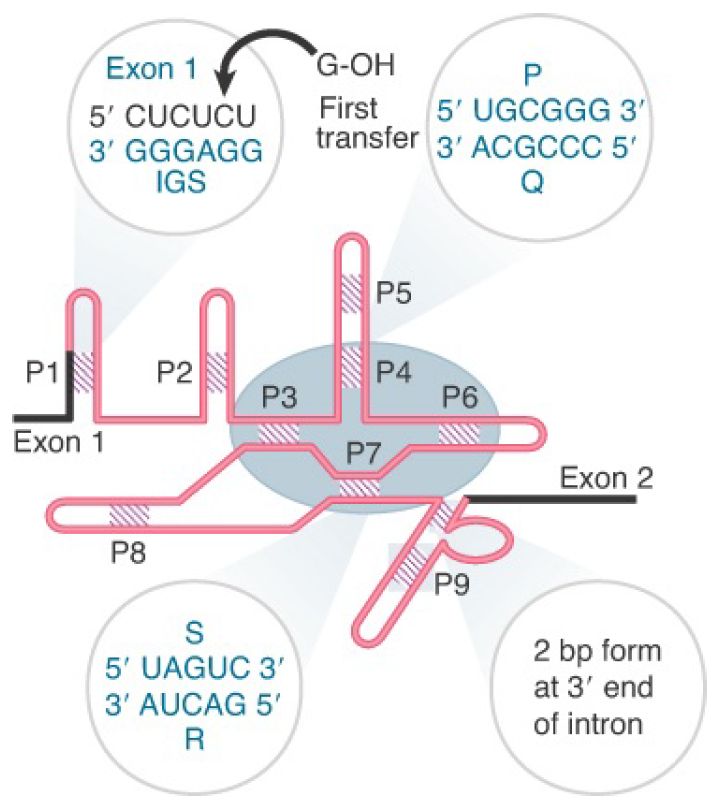
FIGURE 1. Group I introns have a common secondary structure that is formed by nine base-paired regions. The sequences of regions P4 and P7 are conserved and identify the individual sequence elements P, Q, R, and S. P1 is created by pairing between the end of the left exon and the IGS of the intron; a region between P7 and P9 pairs with the 3′ end of the intron. The intron
core is shaded in gray.
Some of the pairing reactions are directly involved in bringing the splice sites into a conformation that supports the enzymatic reaction. P1 includes the 3′ end of exon 1. The sequence within the intron that pairs with the exon is called the internal guide sequence (IGS). The name IGS reflects the fact that originally the region immediately 3′ to the IGS sequence shown in Figure 1was thought to pair with the 3′ splice site, thus bringing the two junctions together. This interaction may occur but does not seem to be essential. A very short sequence—sometimes as short as two bases—between P7 and P9 base pairs with the sequence that immediately precedes the reactive G (ΩG, position 414 in Tetrahymena) at the 3′ end of the intron.
The importance of base pairing in creating the necessary core structure in the RNA is emphasized by the properties of cis-acting mutations that prevent splicing of group I introns. Such mutations have been isolated for the mitochondrial introns through mutants that cannot remove an intron in vivo, and they have been isolated for the Tetrahymena intron by transferring the splicing reaction into a bacterial environment. The construct shown in FIGURE 2 allows the splicing reaction to be followed in E. coli. The selfsplicing intron is placed at a location that interrupts the 10th codon of the β-galactosidase coding sequence. The protein can therefore be successfully translated from an RNA only after the intron has been removed and the correct reading frame restored. The synthesis of β-galactosidase by E. coli in this system indicates that splicing can occur in conditions quite unlike those prevailing in Tetrahymena or even in vitro. Although the group I intron from Tetrahymena can autosplice from the β-galactosidase mRNA in E. coli, it is not clear whether the reaction is assisted by bacterial proteins. In this assay, mutations in the group I consensus sequences that disrupt their base pairing stop splicing and therefore prevent expression of β-galactosidase. The mutations can be reverted by compensating changes that restore base pairing.
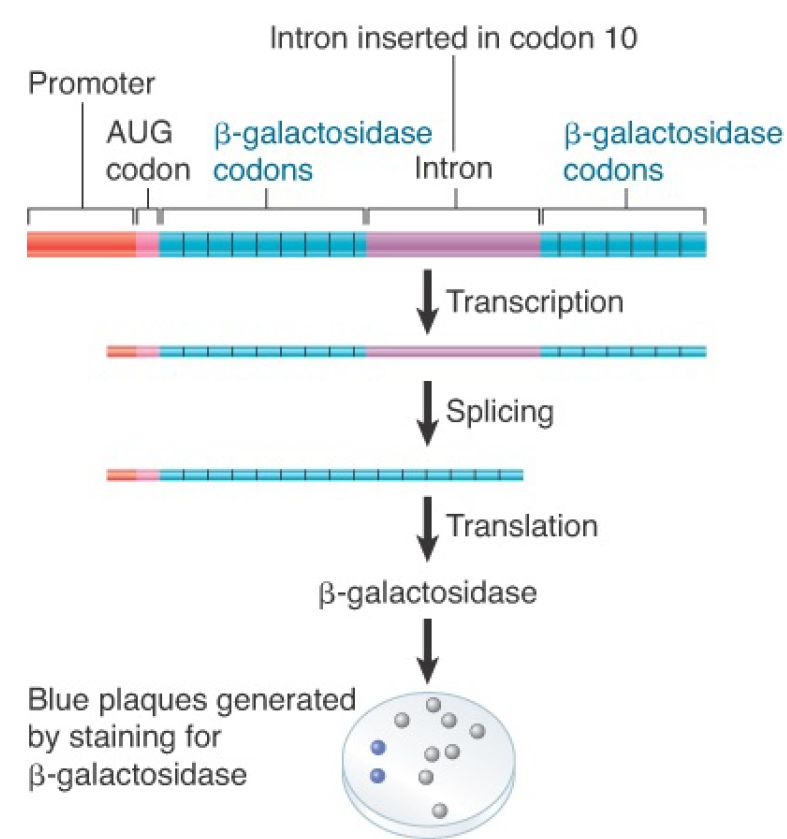
FIGURE 2. Placing the Tetrahymena intron within the β-galactosidase coding sequence creates an assay for self-splicing in E. coli. Synthesis of β-galactosidase can be tested by adding a compound that is turned blue by the enzyme. The sequence is carried by a bacteriophage, so the presence of blue plaques (containing infected bacteria) indicates successful splicing.
Mutations in the corresponding consensus sequences in mitochondrial group I introns have similar effects to those observed in Tetrahymena. A mutation in one consensus sequence may be reverted by a mutation in the complementary consensus sequence to restore pairing; for example, mutations in the R consensus can be compensated by mutations in the S consensus.
Together these results suggest that the group I splicing reaction depends on the formation of secondary structure between pairs of consensus sequences within the intron. The principle established by this work is that sequences distant from the splice sites themselves are required to form the active site that makes selfsplicing possible.

|
|
|
|
مخاطر عدم علاج ارتفاع ضغط الدم
|
|
|
|
|
|
|
اختراق جديد في علاج سرطان البروستات العدواني
|
|
|
|
|
|
|
مدرسة دار العلم.. صرح علميّ متميز في كربلاء لنشر علوم أهل البيت (عليهم السلام)
|
|
|