Grammar
Tenses
Present

Present Simple
Present Continuous
Present Perfect
Present Perfect Continuous
Past
Past Simple
Past Continuous
Past Perfect
Past Perfect Continuous
Future
Future Simple
Future Continuous
Future Perfect
Future Perfect Continuous
Parts Of Speech
Nouns
Countable and uncountable nouns
Verbal nouns
Singular and Plural nouns
Proper nouns
Nouns gender
Nouns definition
Concrete nouns
Abstract nouns
Common nouns
Collective nouns
Definition Of Nouns
Animate and Inanimate nouns
Nouns
Verbs
Stative and dynamic verbs
Finite and nonfinite verbs
To be verbs
Transitive and intransitive verbs
Auxiliary verbs
Modal verbs
Regular and irregular verbs
Action verbs
Verbs
Adverbs
Relative adverbs
Interrogative adverbs
Adverbs of time
Adverbs of place
Adverbs of reason
Adverbs of quantity
Adverbs of manner
Adverbs of frequency
Adverbs of affirmation
Adverbs
Adjectives
Quantitative adjective
Proper adjective
Possessive adjective
Numeral adjective
Interrogative adjective
Distributive adjective
Descriptive adjective
Demonstrative adjective
Pronouns
Subject pronoun
Relative pronoun
Reflexive pronoun
Reciprocal pronoun
Possessive pronoun
Personal pronoun
Interrogative pronoun
Indefinite pronoun
Emphatic pronoun
Distributive pronoun
Demonstrative pronoun
Pronouns
Pre Position
Preposition by function
Time preposition
Reason preposition
Possession preposition
Place preposition
Phrases preposition
Origin preposition
Measure preposition
Direction preposition
Contrast preposition
Agent preposition
Preposition by construction
Simple preposition
Phrase preposition
Double preposition
Compound preposition
prepositions
Conjunctions
Subordinating conjunction
Correlative conjunction
Coordinating conjunction
Conjunctive adverbs
conjunctions
Interjections
Express calling interjection
Phrases
Sentences
Clauses
Part of Speech
Grammar Rules
Passive and Active
Preference
Requests and offers
wishes
Be used to
Some and any
Could have done
Describing people
Giving advices
Possession
Comparative and superlative
Giving Reason
Making Suggestions
Apologizing
Forming questions
Since and for
Directions
Obligation
Adverbials
invitation
Articles
Imaginary condition
Zero conditional
First conditional
Second conditional
Third conditional
Reported speech
Demonstratives
Determiners
Direct and Indirect speech
Linguistics
Phonetics
Phonology
Linguistics fields
Syntax
Morphology
Semantics
pragmatics
History
Writing
Grammar
Phonetics and Phonology
Semiotics
Reading Comprehension
Elementary
Intermediate
Advanced
Teaching Methods
Teaching Strategies
Assessment

Phonemic Analysis: A Mini-demo
 المؤلف:
Mehmet Yavas̡
المؤلف:
Mehmet Yavas̡
 المصدر:
Applied English Phonology
المصدر:
Applied English Phonology
 الجزء والصفحة:
P37-C2
الجزء والصفحة:
P37-C2
 2025-02-26
2025-02-26
 1441
1441




+
-
20
Phonemic Analysis: A Mini-demo
In the following, we will review the points made thus far and briefly show the mechanics of phonemic analysis. When we do a phonemic analysis to establish the phonological status of a pair or a group of sounds (phonetically similar sounds that could potentially be allophones of the same phoneme), it is necessary to examine their distribution. They are either in contrast and belong to separate phonemes, or represent allophones (positional variants) of a phoneme that are in complementary distribution. The first task is to spot the ‘suspicious’ pair or group of sounds. To exemplify this, we look at the sounds [s], [z], and [ʃ] in English and Korean. The three sounds [s, z, ʃ], which can be heard during the conversations of both English and Korean speakers, reveal the needed phonetic similarities. Namely, (a) they all share manner of articulation features (sibilant fricatives); (b) [s] and [z] share place of articulation (alveolar), differing only in voicing; (c) [s] and [ʃ] share voicing (voiceless), differing only in place of articulation. The decision on their distributional character starts with the search for minimal pairs. When we look at English, we find these three sounds in an overlapping distribution, in that we have the following minimal pairs: sip [sɪp] – ship [ʃɪp] – zip [zɪp]. In other words, the sounds in question do occur in the same word position (initial) before the same vowel, [ɪ], and the words mean different things. From this, we can conclude that the three sounds are in contrast and belong to three separate phonemes.
Now, let us examine the situation in Korean. The following data, although limited in scope, are representative of the pattern in the language.

We start the search for the distribution of these sounds in Korean in exactly the same way we started for English, namely by looking for minimal pairs. The examination of the data reveals that here, unlike English, we do not have minimal pairs to establish contrasts. Our next step is to look for near-minimal pairs, in which the immediately preceding and the immediately following environments are the same. We do not seem to have those either. Under such conditions, we list the environments in which the sounds in question appear, and ask whether the sounds occur in the same or similar environments. We do this by putting the preceding environment to the left of a blank, and the following environment to the right of it. The blank itself shows the place that the sound occupies. For example, “# __ a” indicates that [s] occurs in word-initial position (# stands for the word boundary) before the vowel [a], as exemplified in word number (4). When we have more than two sounds in question in the group, it is customary to look at them pairwise. Thus, we start with [s – ʃ]. The numbers next to each environment cited indicate the items from the data above.
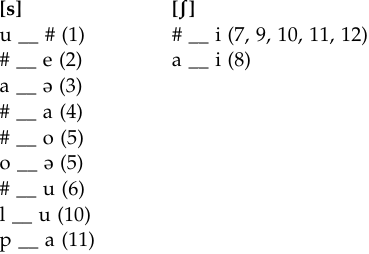
When we examine the distribution of the two sounds in question, we see that they can have the identical context for the preceding environment, namely at the beginning of a word. As for what comes after, we note the following: although both sounds can be followed by a vowel, the vowels are not identical. While [ʃ] always appears before [i], [s] is found before other vowels and never before [i]. Before we decide whether the difference in the following vowel may be significant (that is, contextually create a change), we should remember what was said earlier with regard to the difference between the two sounds. In the case of [s] and [ʃ], the difference lies in the place of articulation only (alveolar and palato-alveolar, respectively). The vowel [i] is known to cause alveolar sounds to change in place of articulation and become palato-alveolar. Thus, what happens in the Korean data is a good example of phonetically motivated contextual change. The fact that we find [ʃ] only before [i], and never find [s] in the same environment, satisfies the requirement of mutual exclusivity of a pair of phonetically similar sounds that are in complementary distribution, and thus they are allophones of the same phoneme.
The next task is to compare [s] and [z], as these two sounds share all features (alveolar, fricative) except for voicing (voiceless and voiced, respectively). Since we already have the environments for [s] listed, we need to look at the occurrences of [z] alone.
ŋ __ ə (13)
n __ a (14)
The listing shows that the following environment is irrelevant, because it can be shared by the two sounds in question ([s] can be followed by an [ə] as in (3) and (5); it can also be followed by [a], as in (4) and (11). The examination of the preceding environment, however, reveals that [z] is always preceded by a nasal, and [s] can never be. Thus, the complementary distribution exhibited by these two phonetically similar sounds leads us to the conclusion that they are allophones of the same phoneme. Because we also said the same thing for the relationship between [s] and [ʃ], the conclusion is that the three sounds are allophones of the same phoneme.
At this juncture, we have another task that relates to the choice of the basic allophone that will represent the phoneme. To determine this, we look at the distribution of the three sounds again and realize that [s] is the one that appears in the most different environments (the least restricted in occurrence). Because [ʃ] occurs only before [i], and [z] occurs only after nasals, [s] is clearly the choice and thus represents the phoneme.
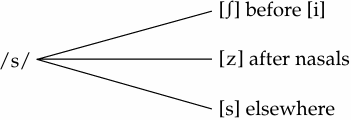
As shown above, the phoneme is represented with diagonal bars / /, and the allophones are represented with brackets, [ ]. Also, in giving the environments for the allophones, we write the more restricted one(s) first, so that we can say “elsewhere” for the basic (the least restricted) allophone of the phoneme.
If we compare the same three sounds in Korean and in English, we see a very different picture. While the sounds in question are in complementary distribution and are allophones of one and the same phoneme in Korean, they are in contrast and belong to three separate phonemes in English. We can illustrate these differences schematically in the following way:
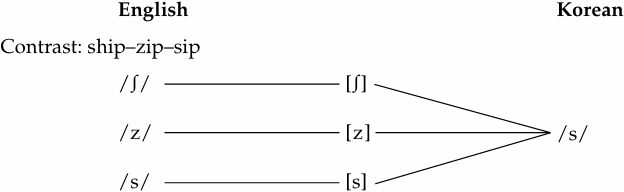
Phonetic similarity: [s] and [z] share the place and the manner of articulation, different in voicing; [s] and [ʃ] share the voicing and the manner of articulation, different in place of articulation.
Allophonic processes: change to [ʃ] before /i/, and to [z] after nasals.
In the displays above, and below, we place the phonetically similar sounds that are shared by the two languages in the middle, between the brackets, [ ]. The language that makes the phonemic contrast has its two (or more) separate phonemes placed in between diagonal bars. With the phoneme symbols, we give a minimal pair to show the contrast. On the other side, the single phoneme of the language is placed. Underneath the display, we have more explicit statements regarding the phonetic similarity of the sounds (suspicious pair), and the type of process for the contextual variants (allophones) that are in complementary distribution. The processes that are responsible for the contextual variants are almost always assimilation processes. Simply defined, assimilation refers to the influence that one sound may have on another when they are contiguous in time. To exemplify this, let us look at the Korean triplet [s, z, ʃ] we discussed earlier. We saw that /s/ was realized phonetically as [ʃ] before /i/. The change shown here is that a voiceless alveolar fricative becomes a voiceless palato-alveolar fricative. If we think about the area that is relevant for the articulation of [i], we realize that it corresponds to the same area where palato-alveolars are made. In other words, the influence of [i] as a conditioning environment for [ʃ] is, phonetically, very plausible, and indeed not infrequent in languages. Since in this case, the conditioning sound, [i], is after the conditioned sound, the process is said to be an example of a regressive assimilation (the following sound influences the preceding sound; called anticipatory coarticulation in some books). If the influence comes from the preceding sound on to the following sound, it is termed a progressive assimilation. The other allophone of the Korean /s/ was [z], and the context it appeared in was always after a nasal. In other words, the voicing of the nasal seems to be the culprit in this change from a voiceless alveolar fricative to a voiced alveolar fricative. Since the conditioning sound, nasal, is before the conditioned sound, alveolar fricative, this is a case of progressive assimilation (called perseverative coarticulation in some books).
Contextual assimilatory changes are not restricted to consonants. For example, Totonac (an Amerindian language spoken in Mexico) has both voiced and voice less vowels that are in complementary distribution. We find voiceless vowels in final position and the others elsewhere. The final devoicing of vowels can be considered as an assimilatory event, as it displays a situation in which the vowel in final position is influenced by what comes after it (i.e. ‘silence’, which does not have vocal cord vibration).
Another case of a complementary distribution relating to vocalic segments can be given from English. In certain dialects, the diphthong /aɪ/ has two phonetic manifestations, [aɪ] and [Λɪ], as seen in the following.
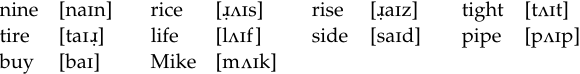
What we see here is that [Λɪ] is found before /s, t, f, p, k/, and [aɪ] is found elsewhere. Thus, the characterization of this systematic change is “the diphthong is [Λɪ] if it is followed by a voiceless sound; otherwise, it is [aɪ]”.
The conditioning environment is not always restricted to either the preceding or the following environment; sometimes the effects come from both environments. For example, in Cree (an Amerindian language spoken in Canada) [p] and [b] are in complementary distribution. We find [b] intervocalically (between two vowels) and [p] elsewhere. This clearly tells us that the assimilatory conditioning environment is from both the preceding and the following environments; the voiced allophone [b] is found in between two vowels, which are voiced.
Now, let us examine the two cases – Malayalam–English for dental and alveolar nasals, and Spanish–English for dental/alveolar stops and fricatives– that we referred to earlier.
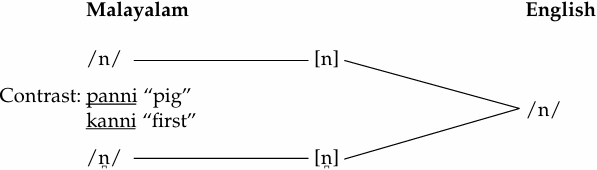
Phonetic similarity: shared voicing and manner of articulation; different in place of articulation.
Allophonic process: nasal becomes dental before /θ, ð/ (interdentals). Regressive assimilation.

Phonetic similarity: shared place of articulation and voicing; different in manner of articulation.
Allophonic process: a stop becomes a fricative (more open articulation) between two vowels. Both the preceding and following environments are relevant.
The cases above, which show that the same phonetic reality is interpreted differently phonologically in different languages, are not limited to these pairs of sounds and contexts and can easily be multiplied cross-linguistically. The following are some examples between different pairs of languages:

Phonetic similarity: shared place and manner of articulation; different in voicing. Allophonic process: voicing between two vowels. Both the preceding and the following environments are relevant.
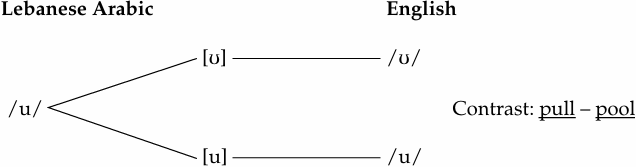
Phonetic similarity: both high, back, round; different in tense/lax. Allophonic process: lowering (laxing) in final position.

Phonetic similarity: shared manner of articulation and voicing; different in place of articulation.
Allophonic process: nasal becomes velar before velars. Regressive assimilation.

Phonetic similarity: all features shared, except for lateral.
Allophonic process: liquid becomes non-lateral intervocalically. Both the preceding and following environments are relevant.
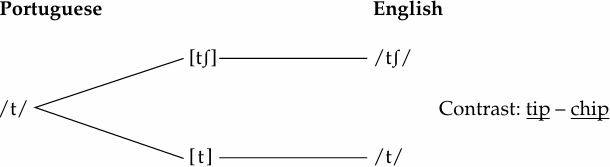
Phonetic similarity: both voiceless obstruents; [tʃ] palato-alveolar affricate, [t] alveolar stop.
Allophonic process: an alveolar stop becomes a palato-alveolar affricate before /i/. (Since there are no palato-alveolar stops in Portuguese, the affricate is the closest sound. Palato-alveolar place is in the vicinity of the vowel area for /i/.) Regressive assimilation.
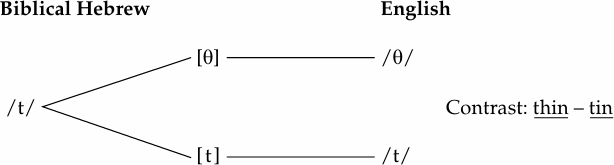
Phonetic similarity: dental/alveolar. Voiceless, obstruents; different in manner of articulation.
Allophonic process: a stop becomes a fricative (more open articulation) inter-vocalically. Both the preceding and the following environments are relevant.
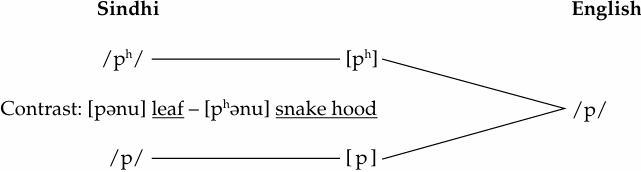
Phonetic similarity: all features shared, except for aspiration.
Allophonic process: aspirate a voiceless stop at the beginning of a stressed syllable.
The following examples have some other relationships that do not have an exact point of reference in English, but reveal certain phonetically significant allophonic processes.
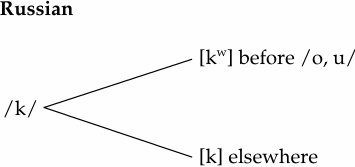
Phonetic similarity: both voiceless velar stops; different in labialization.
Allophonic process: labialize (add lip rounding to) the velar stop before /o, u/ (rounded vowels). Regressive assimilation.
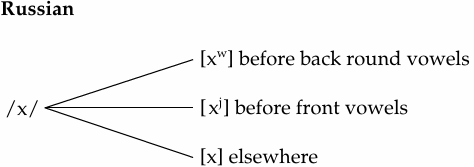
Phonetic similarity: all voiceless velar fricatives; different in labialization or palatalization.
Allophonic process: labialize (add lip rounding to) the sound before a rounded vowel, and palatalize it (more forward articulation, like adding an [i]-like quality) before a front vowel. Regressive assimilation.

Phonetic similarity: both alveolar r-sounds; different in voicing.
Allophonic process: devoice an r-sound next to a voiceless stop, or word-finally (also a voiceless environment). Regressive assimilation.
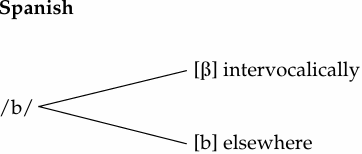
Phonetic similarity: shared voicing and place of articulation; different in manner of articulation (stop/fricative).
Allophonic process: a stop becomes a fricative (more open articulation) between two vowels. Both the preceding and the following environments are relevant.

Phonetic similarity: both voiceless fricatives; different in place of articulation (velar/palatal).
Allophonic process: move a fricative to a more front articulation after a front vowel. Progressive assimilation.
To sum up what has been said so far, we can say:
(a) The goal of any phonemic (phonological) analysis is to determine the relationship between two or more sounds in a language.
(b) Two languages may share the same sounds, but arrange them differently. That is, phonetic identity does not result in phonemic identity.
(c) Allophones of the same phoneme in a language must be phonetically similar and be in complementary distribution.
(d) Realizations of different phonemes are in overlapping distribution, and are in contrast. That is, they must be capable of changing the meaning of a word if substituted for each other.
 الاكثر قراءة في Phonology
الاكثر قراءة في Phonology
 اخر الاخبار
اخر الاخبار
اخبار العتبة العباسية المقدسة

الآخبار الصحية


مواضيع ذات صلة
 قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة
قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة "المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة
"المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة (نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)
(نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)