Grammar
Tenses
Present

Present Simple
Present Continuous
Present Perfect
Present Perfect Continuous
Past
Past Simple
Past Continuous
Past Perfect
Past Perfect Continuous
Future
Future Simple
Future Continuous
Future Perfect
Future Perfect Continuous
Parts Of Speech
Nouns
Countable and uncountable nouns
Verbal nouns
Singular and Plural nouns
Proper nouns
Nouns gender
Nouns definition
Concrete nouns
Abstract nouns
Common nouns
Collective nouns
Definition Of Nouns
Animate and Inanimate nouns
Nouns
Verbs
Stative and dynamic verbs
Finite and nonfinite verbs
To be verbs
Transitive and intransitive verbs
Auxiliary verbs
Modal verbs
Regular and irregular verbs
Action verbs
Verbs
Adverbs
Relative adverbs
Interrogative adverbs
Adverbs of time
Adverbs of place
Adverbs of reason
Adverbs of quantity
Adverbs of manner
Adverbs of frequency
Adverbs of affirmation
Adverbs
Adjectives
Quantitative adjective
Proper adjective
Possessive adjective
Numeral adjective
Interrogative adjective
Distributive adjective
Descriptive adjective
Demonstrative adjective
Pronouns
Subject pronoun
Relative pronoun
Reflexive pronoun
Reciprocal pronoun
Possessive pronoun
Personal pronoun
Interrogative pronoun
Indefinite pronoun
Emphatic pronoun
Distributive pronoun
Demonstrative pronoun
Pronouns
Pre Position
Preposition by function
Time preposition
Reason preposition
Possession preposition
Place preposition
Phrases preposition
Origin preposition
Measure preposition
Direction preposition
Contrast preposition
Agent preposition
Preposition by construction
Simple preposition
Phrase preposition
Double preposition
Compound preposition
prepositions
Conjunctions
Subordinating conjunction
Correlative conjunction
Coordinating conjunction
Conjunctive adverbs
conjunctions
Interjections
Express calling interjection
Phrases
Sentences
Clauses
Part of Speech
Grammar Rules
Passive and Active
Preference
Requests and offers
wishes
Be used to
Some and any
Could have done
Describing people
Giving advices
Possession
Comparative and superlative
Giving Reason
Making Suggestions
Apologizing
Forming questions
Since and for
Directions
Obligation
Adverbials
invitation
Articles
Imaginary condition
Zero conditional
First conditional
Second conditional
Third conditional
Reported speech
Demonstratives
Determiners
Direct and Indirect speech
Linguistics
Phonetics
Phonology
Linguistics fields
Syntax
Morphology
Semantics
pragmatics
History
Writing
Grammar
Phonetics and Phonology
Semiotics
Reading Comprehension
Elementary
Intermediate
Advanced
Teaching Methods
Teaching Strategies
Assessment

Features and classes of segments
 المؤلف:
David Odden
المؤلف:
David Odden
 المصدر:
Introducing Phonology
المصدر:
Introducing Phonology
 الجزء والصفحة:
61-3
الجزء والصفحة:
61-3
 25-3-2022
25-3-2022
 1713
1713




+
-
20
Features and classes of segments
Besides defining phonemes, features play a role in formalizing rules, since rules are stated in terms of features. Every specification, such as [+nasal] or [-voice], defines a class of segments. The generality of a class is inversely related to how many features are required to specify the class, as illustrated in (19).

The most general class, defined by a single feature, is [+syllabic] which refers to all vowels. The size of that class is determined by the segments in the language: [+syllabic] in Spanish refers to [i e a o u], but in English refers to [i ɪ e ε æ a ɔ o ʊ u ə ʌ r̩ l̩]. As you add features to a description, you narrow down the class, making the class less general. The usual principle adopted in phonology is that simpler rules, which use fewer features, are preferable to rules using more features.
One challenge in formalizing rules with features is recognizing the features which characterize classes. Discovering the features which define a class boils down to seeing which values are the same for all segments in the set, then checking that no other segment in the inventory also has that combination of values. The main obstacle is that you have to think of segments in terms of their feature properties, which takes practice to become second nature. As an exercise towards understanding the relation between classes of segments and feature descriptions, we will assume a language with the following segments:
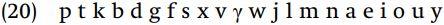
To assist in solving the problems which we will consider, feature matrices of these segments are given below in (21).
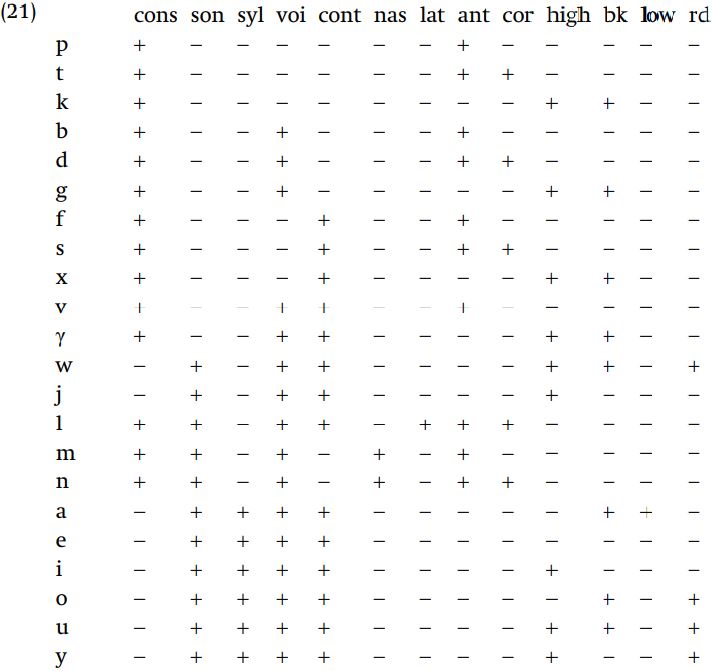
Each of the following sets of segments can be defined in terms of some set of distinctive features.

In the first set, each segment is a voiceless obstruent, and, equally importantly, every voiceless obstruent of the language is included in this first set. This set could be specified as [-sonorant, -voice] or as [-voice], since all voiceless segments in the language are [-sonorant]. Given that both specifications refer to exactly the same segments, there is no question of one solution being wrong in the technical sense (assuming the language has the segments of (20): if the language had [h], these two feature specifications would not describe the segments). However, unless there is a compelling reason to do otherwise, the simplest definition of the set of segments should be given, using only those features which are absolutely necessary. The features which are used to exactly define a set of segments depends very much on what the entire set of segments in the language is. If we were dealing with a language which had, in addition, the segments.
[ph t h kh ], then in specifying the set [p t k f s x], you would have to also mention [-s.g.] in order to achieve a definition of the set which excludes [ph t h kh ].
The set (22ii) contains only consonants (i.e. [-syllabic] segments), but it does not contain all of the [-syllabic] segments of the language. Compare the segments making up (22ii) with the full set of consonants:
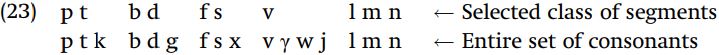
This set does not include glides: [consonantal] is the essential property which distinguishes glides (including h and ʔ, which are lacking here) from regular consonants. Thus, the segments in (ii) are [+consonantal]. But not all [+consonantal] segments are included in set (ii): the velars are not included, so we need a further restriction. The features typically used to specify velars are [+high, +back] so we can use one of those features. Thus, you can pick out the segments in (ii) as the class of [+consonantal, -high] segments, or the [+consonantal, -back] segments. Rather than refer to [consonantal], you could try to take advantage of the fact that all glides are [+high] and refer to (ii) as the set of [-high] segments, without mentioning [consonantal]. It is true that all segments in the set are [-high], but [-high] itself cannot be the entire description of this set since not all [-high] segments of the language are in the set: the vowels {aeo} are not in set (ii). We conclude that [+consonantal, -high] is the correct one for this class of segments.
Set (iii) contains a mixture of vowels and consonants: it includes all vowels, plus the nasals, the lateral [l], and the glides. This class is defined by [+sonorant]. Another feature which is constant in this group is [+voice], so you could define the class as [+sonorant, +voice]. But addition of [+voice] contributes nothing, so there is no point in mentioning that feature as well. Set (iv) on the other hand contains only obstruents, but not all obstruents. Of the whole set of obstruents, what is missing from (iv) is the group {tds}, which are [+coronal]. Therefore, we can refer to set (iv) by the combination [-sonorant, -coronal].
The fifth set, {j l m n a e i}, includes a mixture of vowels and consonants. Some properties that members of this set have in common are that they are voiced, and they are sonorants. Given the phoneme inventory, all sonorants are voiced, but not all voiced segments are sonorants. Since the voiced obstruents {bdgv γ} are not included in this set, it would be less efficient to concentrate on the feature [+voice], thus we focus on the generalization that the segments are sonorants. Now compare this set to the total set of sonorants.
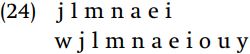
We can see that this set of segments is composed of a subset of sonorants, namely the sonorants excluding {w, o, u, y}. But that set is the set of [+round] segments; therefore, the set is the set of [+sonorant, -round] segments.
The last set also contains a mixture of consonants and vowels: it includes all of the vowel and glides, plus the voiced obstruents {v, γ}. Therefore, the feature [sonorant] cannot be used to pick out this class of segments, since members of the class can have both values for that feature. However, all of the members of this class are voiced. Now compare set (vi) against the set of all voiced segments.
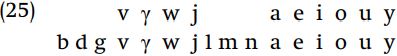
The fundamental difference between [b] and [v], or between [g] and [γ], is that {b, g} are stops while {v, γ} are continuants. This suggests using [+continuant] as one of the defining features for this class. Vowels and glides are all [+continuant], so we have passed the first test, namely that all segments in set (vi) are [+continuant, +voice]. We must also be sure that this is a sufficient specification for the class: are there any [+continuant, +voice] segments in the language which are not included in set (vi)? The segments to worry about in this case would be {l, m, n}, which are [+voice]. We exclude the nasals via [+continuant] and add [-lateral] to exclude l.
As a further exercise in understanding how sets of segments are grouped by the features, assume a language with the following segmental inventory.
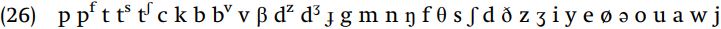
For each group, determine what feature(s) define the particular set of segments.
 الاكثر قراءة في Phonology
الاكثر قراءة في Phonology
 اخر الاخبار
اخر الاخبار
اخبار العتبة العباسية المقدسة

الآخبار الصحية


مواضيع ذات صلة
 قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة
قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة "المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة
"المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة (نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)
(نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)